
Beyond Transformers
A dive into the GPT, BERT and BART architectures.

After the transformer architecture, there were several architectures built on top of the Attention mechanism that aimed to solve several problems. In this blog we take a look at a few of these architectures: GPT, BERT and BART.
Note: This blog is part 2 of a series of blogs that I’m writing which breakdown the technology/architecture used in modern LLMS.
Part 1 explains the Transformer architecture.
Let’s get started.
GPT
GPT stands for Generative Pre-trained Transformer (see: paper). Modern LLMS like ChatGPT, Llama, Gemini etc are built on top of this architecture.
GPT is a decoder-only transformer that is autoregressive.
It predicts the next token in a sequence given all previous tokens. The key idea is to leverage unsupervised pre-training on large corpora and then perform supervised fine-tuning (SFT) on specific tasks such as question-answering.
GPT uses masked self-attention to predict tokens auto-regressively. Each token can only attend to previous tokens. This allows the model to build context from what has already been generated while preventing future token leakage.
Stages involved
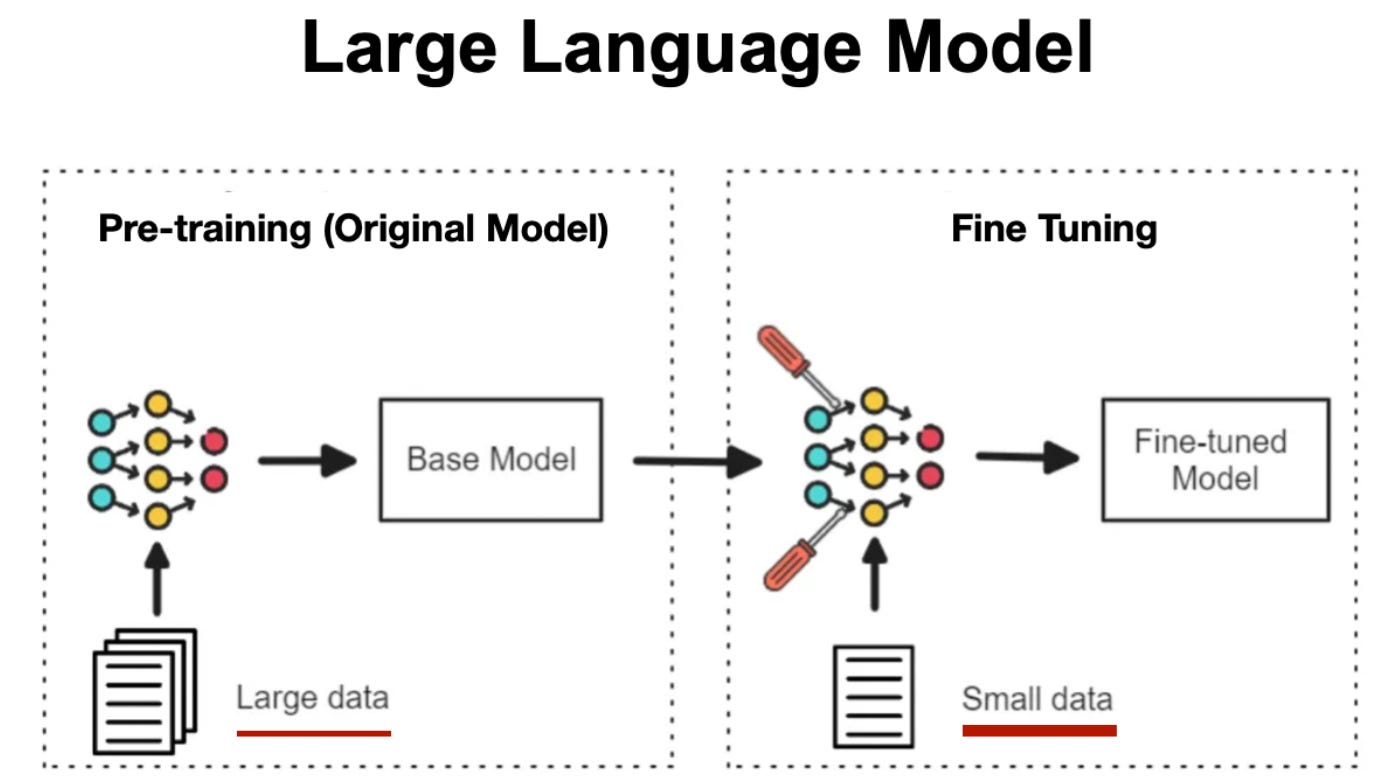
Pre-training (Unsupervised):
1. Input tokens → embeddings + positional encodings
2. Multiple decoder blocks (masked self-attention + feedforward networks)
3. Linear projection → Softmax → next token probabilities
4. Teacher forcing: at each time step, the correct token is provided as input for predicting the next token
5. Loss: cross-entropy between predicted probabilities and true tokens
Supervised Fine-Tuning (SFT):
1. Input sequence: task-specific text (e.g., question and answer)
2. Target: desired output (e.g., answer)
3. The same embedding and decoder weights are used
4. Each token in the input sequence is converted to embeddings
5. Teacher forcing continues: at each step, the correct target token is provided to predict the next
6. Fine-tuning updates weights to align pre-training knowledge with the task
We shall take a look at pre-training and fine-tuning later in detail.
For now let us look at the decoder architecture that is used in both of the training parts.
Decoder
Since it is built on the same decoder as the transformer, it uses the Masked Multi-Head Self-Attention architecture , here is a quick recap of the Decoder.
The decoder-only architecture consists of stacked blocks:
1. Masked Multi-Head Self-Attention
2. Residual connection + LayerNorm
3. Feedforward network
4. Residual connection + LayerNorm
5. Linear projection + Softmax
Pre-training and Fine-Tuning
Pre-training
Any GPT is first trained on a huge corpus of text containing sentences.
Its training objective is to predict the next token.
Pretraining is done to build up context about the language to the transformer.
By training on a huge corpus of data to predict the next token, the model understands when to generate tokens given a piece of context. It understands the semantics of tokens and the language. It learns to predict when and how a token shows up given a context.
Pre-Training Objective:
The objective is to maximize the following likelihood:
where k is the size of the context window, and the conditional probability P is modeled using a neural network with parameters Θ.
These parameters are trained using stochastic gradient descent.
For Example:
Given the sentence ‘The capital of France is’, the model would predict the token ‘France’.
Pre-training is achieved by training a huge corpus of language data so that the model understands the language.
Supervised Fine-Tuning
After building an understanding of the language using pre-training, we fine-tune the model so that it can perform specific tasks. The most commonly used task is Q and A wherein you ask/prompt an llm a question and it answers.
Fine-tuning is done by training the already trained weights/embeddings on specific use-case data. In the case of Q and A, you give it Question-Answer pairs so that it can learn to answer the questions from the facts/language build-up in the Fine Tuning stage.
Suppose we have an input sequence:
For which, we want the model to give us the output y, then the learning objective is:
Given an input sequence, the model should give high probability to the output y.
Auxiliary Loss
During fine tuning, we use an auxiliary loss function along with the task specific loss function. This is so that the model retains what it has learnt during the pre-training stage and to avoid overfitting.
TheAuxiliary loss function ensures that the model doesn’t forget the language model it has built in the pre-training stage and instead uses this to learn the task it is being trained for.
So during Fine Tuning we use a task specific loss:
And an auxiliary loss (which is the same as the loss we used in pretraining):
The total loss that we train for is:
where λ is the balance weight that controls how much of auxiliary loss we want the model to be influenced by.
Token Prediction
Context vector from final decoder block:
Linear projection of this to compute Logits:
Softmax gives probabilities over vocabulary:
The most probable token is selected (greedy, sampling, or beam search)
Okay now that we’ve seen the architecture, let us see why this works and build an intuitive understanding.
Why this works:
1. Pre-training:
- Learns general language patterns, syntax, semantics, and world knowledge.
- Each token attends to relevant context which build up rich contextual embeddings.
2. Fine-tuning:
- Updates weights to adapt general knowledge to specific tasks
- Input/output sequences mapped to pre-trained embeddings, allowing transfer learning.
3. Autoregression + Teacher Forcing:
- Gradually builds sequence understanding
- Prevents the model from “cheating” by seeing future tokens
- Enables robust next-token prediction and Q/A generation
Intuitive Understanding:
Pre-training is like training a child on the vocabulary of a language where they the model tries to replicate how certain words are used in certain contexts.
Fine-tuning is like teaching the child to form full fledged sentences and answer questions based on the language learnt.
GPT powers modern LLMs through autoregressive next-token prediction, making it ideal for generation tasks like chatbots and coding assistants. But it lacks bidirectional understanding, which is where BERT comes in, which is built for understanding context deeply rather than generating tokens.
BERT
Bi-Directional Encoder Representations from Transformers (BERT) uses the transformer architecture specifically to understand language and build up an understanding of the input data.
Since it is an encoder only architecture, its purpose is to specifically build up an understanding of the input corpus. Traditionally, transformers process text sequentially from left to right.
However, this is often limiting the model to understand true language understanding. So, BERT uses a bi-directional approach considering both the left and right context of words in a sentence, instead of analyzing the text sequentially, BERT looks at all the words in a sentence.
It uses a bi-directional self attention mechanism.
To make BERT look at tokens in both directions in a sentence, we remove the traditional no-look mask training objective and introduce two pre-training objectives:
Pre-Training Objectives:
Masked Language Modeling:
Randomly mask some fraction of input tokens with a special (mask) token. The token chosen can be either replaced with (mask) or replaced with a random token or kept unchanged.
At any point, 15% of the tokens are masked. So the training objective is to predict the correct token inplace of this (mask) token or the wrong token that is replaced.
The model tries to predict those masked tokens using both left and right context.
Next Sentence Prediction :
MLM gives token-level bi-directionality, but BERT also needs sentence-level coherence for tasks like QA and entailment.
BERT is given sentence pairs, 50% of the time the actual sentence that follows is given and the other 50% of time its a random sentence from the corpus. BERT must predict a binary label saying: if B that follows A is the correct sentence or not.
MLM helps the model understand tokens on the basis of both past and future (left and right) whereas NSP uses that understanding of tokens and applies it to it understanding relations between entire sentences.
The final pre-training loss is the sum of MLM and NSP loss.
BERT is mostly used for tasks that require rich contextual understanding and NLP tasks like text summarization, semantic analysis, text classification etc.
BART
Bi-directional Auto-Regressive Transformer is an auto-encoder which takes in corrupted version of a text sequence into its encoder, maps it to a latent space after which the decoder is responsible to generate the corrected version of the text.
BART can be seen as kind of a mixture of BERT and GPT wherein we make use of the bidirectional encoder and generative decoder.
Encoder
The encoder takes in a sequence of tokens which are corrupted. To teach the model to reconstruct meaning from noisy input, BART deliberately corrupts the input sequence.
Many types of corruptions are applied like:
Token masking (like BERT MLM)
Token deletion
Token permutation / shuffling
Text infilling (span masking)
Sentence permutation
The encoder then produces contextual embeddings for each corrupted token which contains the semantic meaning of tokens and the relationships between tokens.
It uses Self-Attention.
Decoder
The decoder is then trained to generate the correct text sequence using teacher forcing (by shifting tokens one step to the right).
It uses Masked self-attention and Cross-attention to decode the outputs and generate a token.
This architecture is kind of similar to the original Transformer architecture except the fact that the training objective in the encoder was next-token prediction whereas here it is to take in a corrupted/noisy text sequence and generate a corrected version.
An example to see how BART takes in corrupted input and returns original text:
Corrupted input:
“The (MASK) brown (MASK) jumps over the lazy”
Original text to be trained on/generated:
“The quick brown fox jumps over the lazy fox”
Why this objective works:
Bidirectional encoder learns contextual representations even with missing/shuffled tokens
Decoder learns to generate coherent text based on the encoder context.
This forces the model to understand structure and semantics even better than just generating the next token.
BART blends GPT’s generation with BERT’s understanding, making it strong for seq2seq tasks like summarization and translation.
Conclusion
GPT, BERT, and BART form the foundation of modern LLMs. These architectures paved the way for today’s powerful language models that can understand, reason, and generate with remarkable fluency. In the next blog I will probably talk about scaling or some optimization techniques.
That's it for this blog. Thanks for reading and see you soon!
Thanks, my brain can finally conect this from Part 1.
cool